

소프트웨어 마에스트로 컨퍼런스 발표 (22.05.10) 소프트웨어 마에스트로 세미나(야간자율학습 팀) 발표 (22.07.03) CNU SW Academy 발표 (22.07.06) 발표 REPO
안녕하세요. 프론트엔드 개발자 이현진입니다. 오늘 이야기할 주제는 '웹은 어떻게 발전했는가'입니다.

발표는 우선 웹의 역사를 먼저 살펴보고, 그 후에는 브라우저에 관해서 이야기 해보고, 마지막으로 렌더링 프로세스에 대해서 이야기 해보려고 합니다.

인터넷과 웹은 같을까요? 다를까요?

다릅니다. 인터넷이 도시이면 웹은 그 도시 위에있는 건물 하나입니다.

인터넷이 운영체제라면 웹은 그 위에서 실행되는 프로그램 하나입니다.
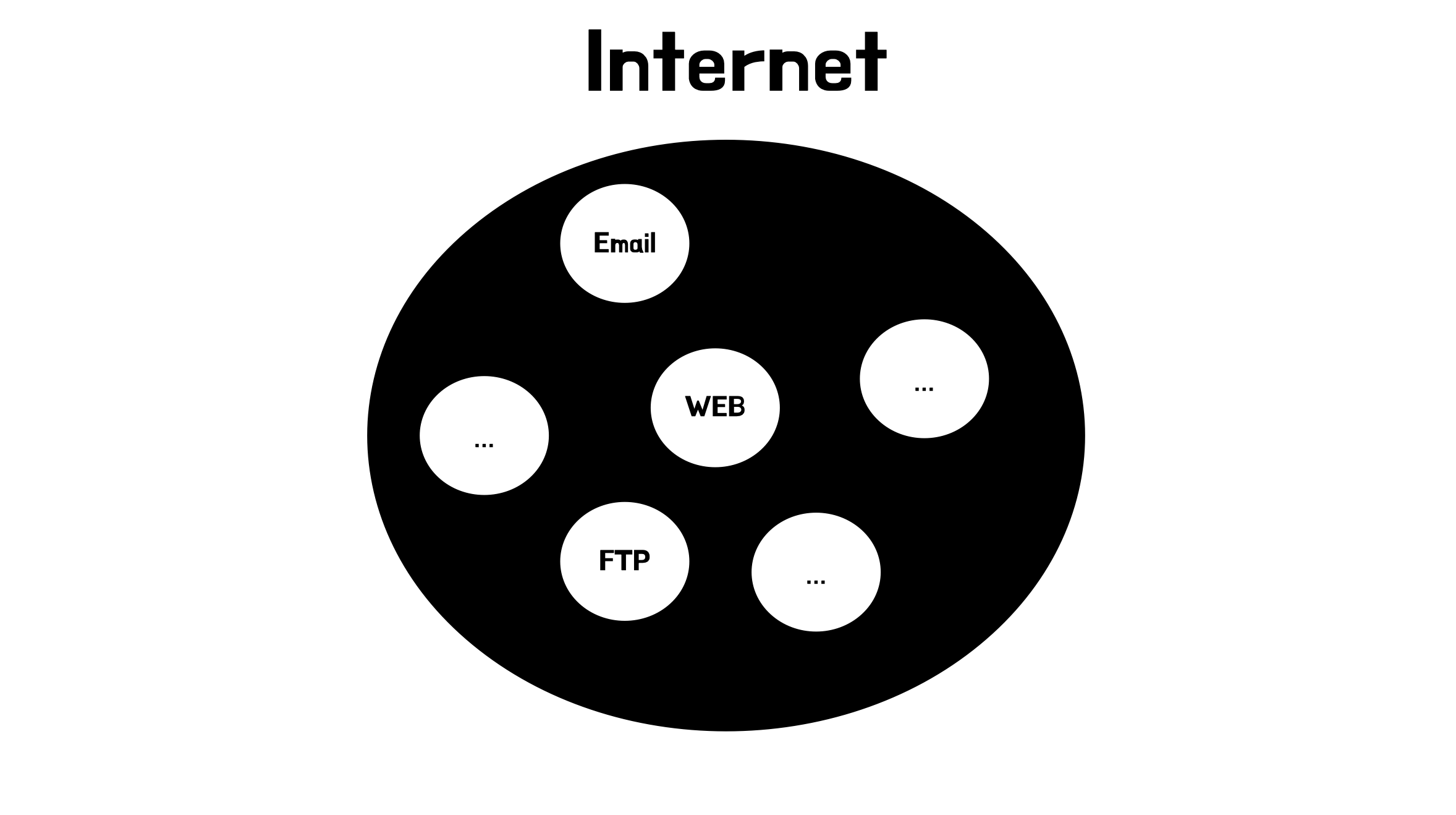
인터넷이라는 전체안에 웹이라는 부분이 존재하고 웹과 동급인 여러가지 서비스들이 있고 이 세가지 이외에도 수많은 서비스들이 존재합니다.

이제 웹이야기를 해보겠습니다. 이분은 웹의 아버지라고 불리는 분입니다. (팀 버너스 리)

팀 버너스 리는 1990년 10월에 세계 최초로 웹페이지를 만드는 편집기를 만듭니다.
바로 다음달인 11월에 세계 최초의 웹 브라우저인 World Wide Web이라는 프로그램을 만듭니다. 이 프로그램은 위와 같이 생겼습니다.
또 다음달인 12월 24일 팀 버너스리는 웹서버라는 프로그램을 만들고, 그 프로그램이 설치되어있는 컴퓨터에 info.cern.ch라고 하는 주소를 부여합니다. 접속하면 위와 같이 나옵니다.
웹의 고향에 오신 것을 환영합니다.

이제 현대의 웹으로 잠깐 점프를 하도록 하겠습니다.
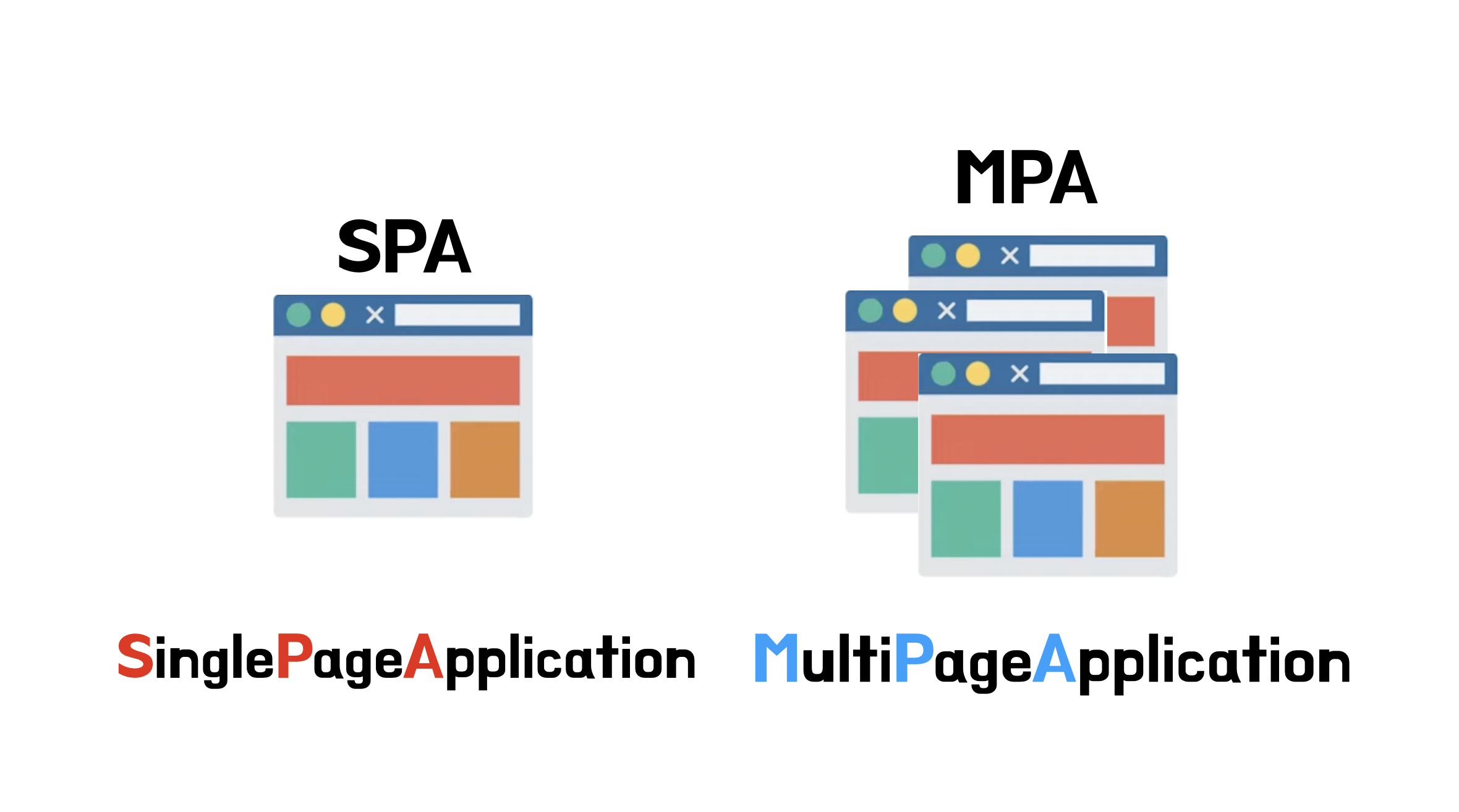
오늘날의 웹은 크게 SPA(Single Page Application)과 MPA(Multi Page Application)으로 나뉩니다.
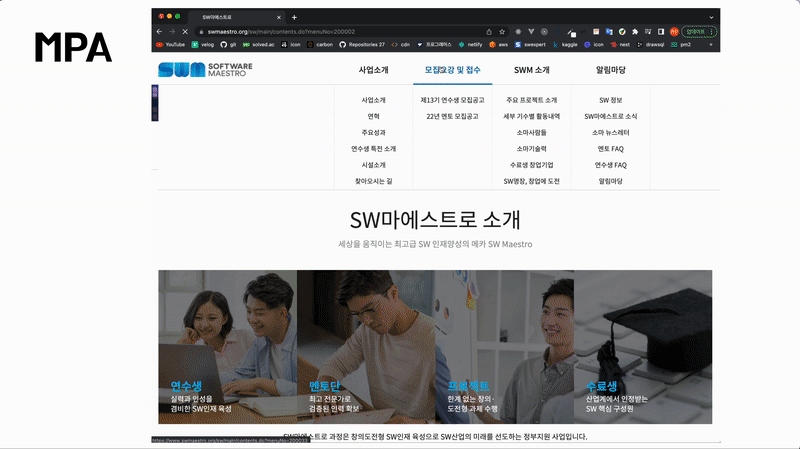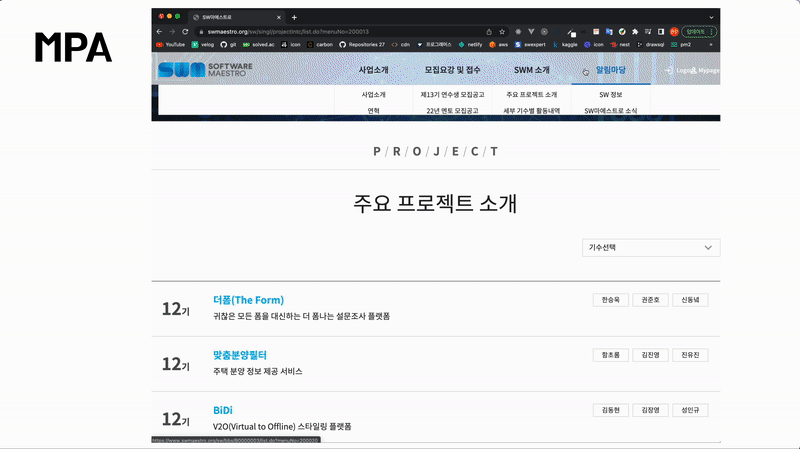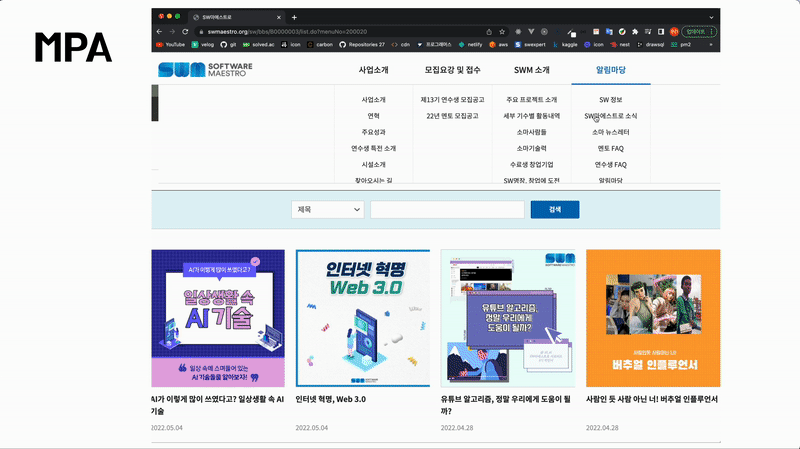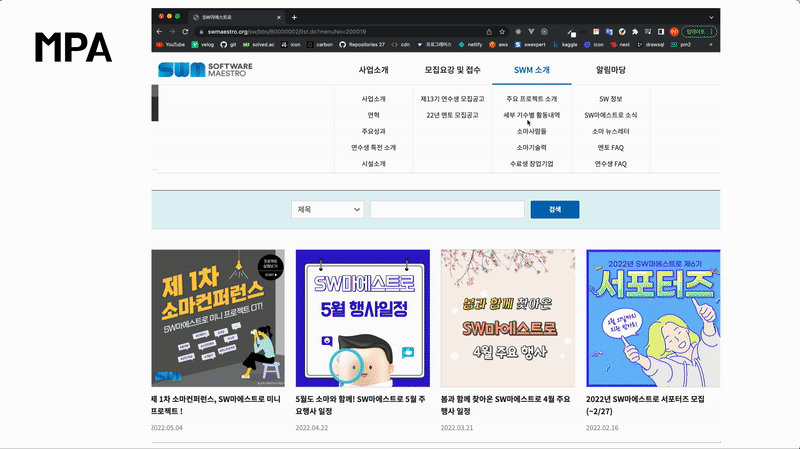
위 홈페이지는 MPA입니다. 링크를 클릭할 때마다 깜빡거리는 현상을 볼 수 있습니다. MPA는 탭을 이동할 때마다 서버로부터 새로운 html을 받아와서 페이지 전체를 새로 렌더링하는 전통적인 웹 페이지 구성 방식입니다.
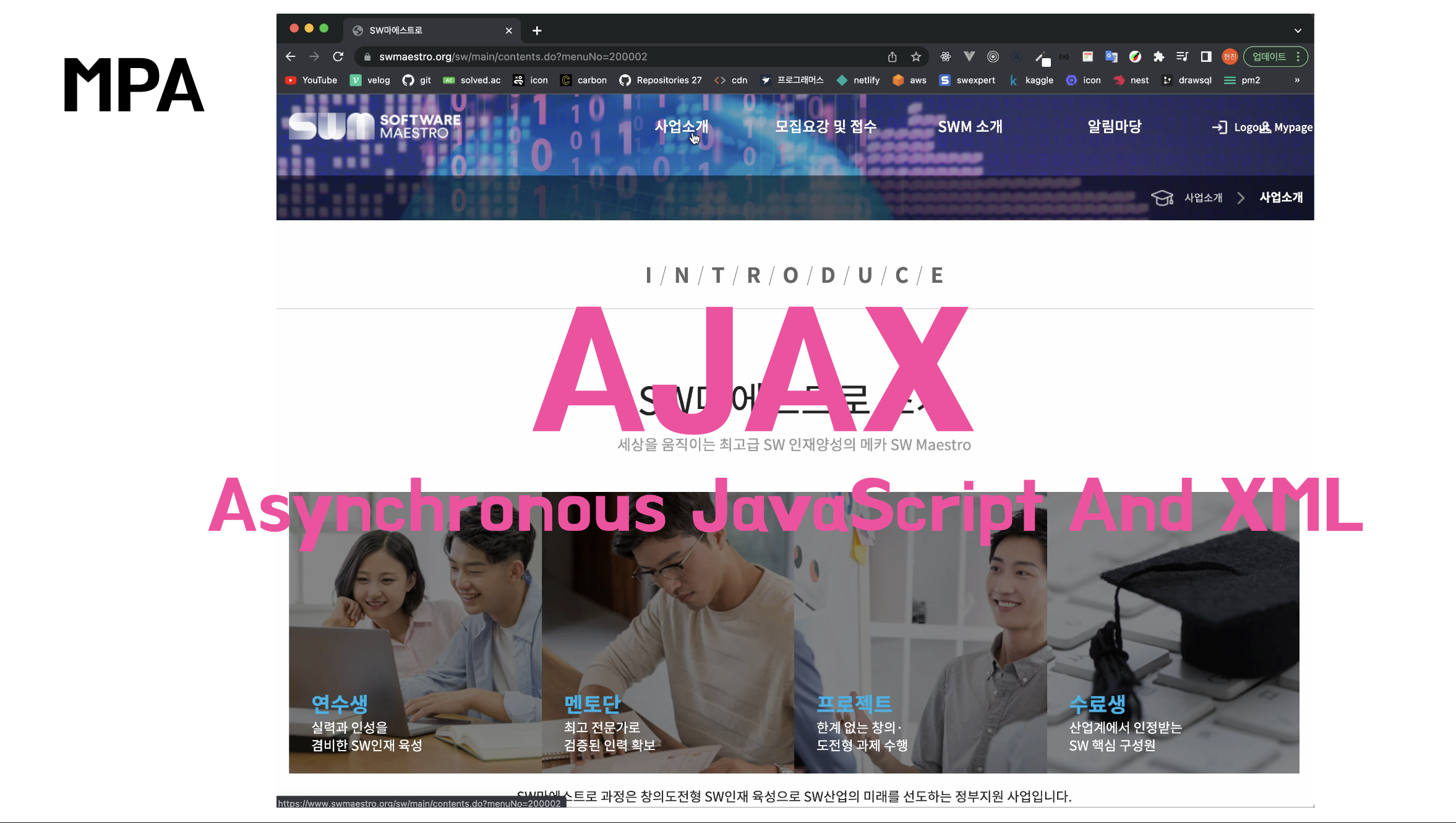
이런 MPA의 단점 때문에 AJAX가 등장하면서부터는 원하는 부분만 클라이언트에서 동적으로 갈아끼울 수 있고 화면 깜빡임도 없는 SPA의 형태로 점차 바뀌게 되었습니다.
AJAX란 Asynchronous JavaScript And XML의 약자로 비동기 자바스크립트와 XML을 말합니다. 간단히 말하면, 서버와 통신하기 위해 XMLHttpRequest 객체를 사용하는 것을 말합니다. JSON, XML등 다양한 포맷을 주고 받을 수 있습니다. AJAX의 강력한 특징은 페이지 전체를 리프레쉬하지 않고도 수행되는 비동기성입니다. 이러한 비동기성을 통해 사용자의 이벤트가 있으면 전체 은페이지가 아닌 일부분만을 업데이트 할 수 있게 해줍니다.

SPA는 하나의 페이지로 구성된 웹 애플리케이션입니다. 오늘날의 SPA는 대부분 React, Vue, Angular를 활용해서 만들어집니다. SPA는 웹 애플리케이션에 필요한 모든 정적 리소스를 최초 한번에 다운도르 합니다. 그 이후 새로운 페이지 요청이 있을 경우, 페이지 갱신에 필요한 데이터만 전달받아 페이지를 갱신합니다. 어떤 링크를 클릭한다해도 그에 관련된 모든 파일을 다운로드 받는게 아니라, 필요한 정보만 받아서 그 정보를 기준으로 업데이트 할 뿐입니다.
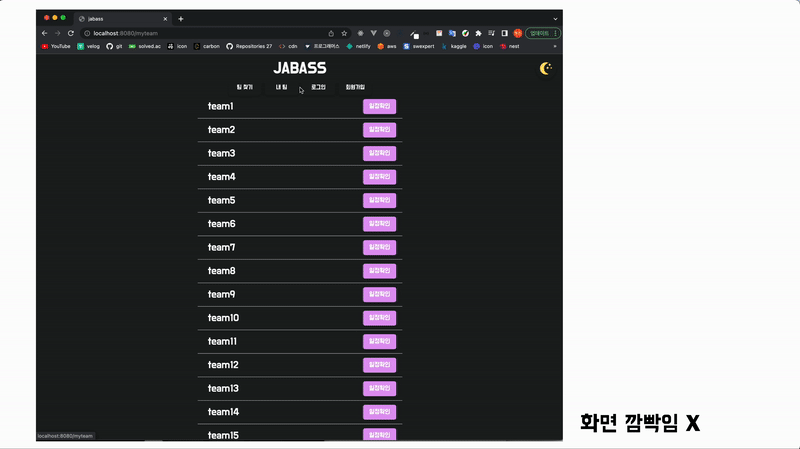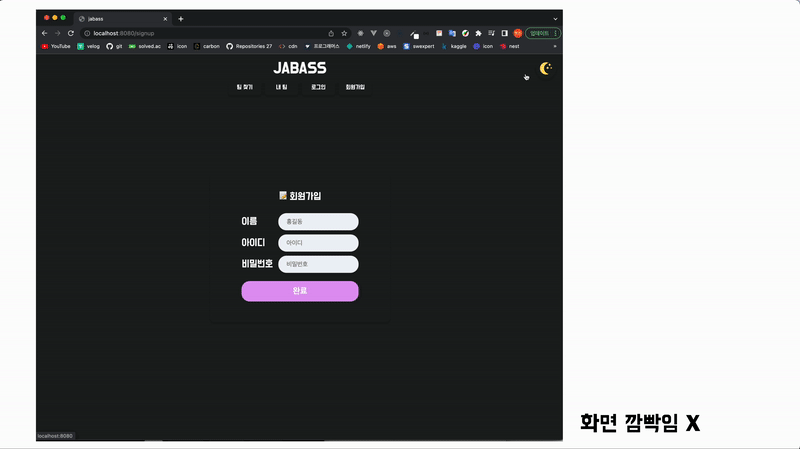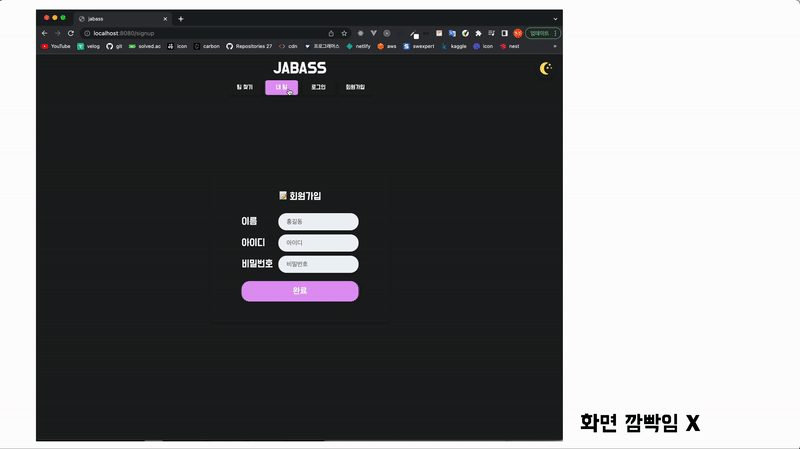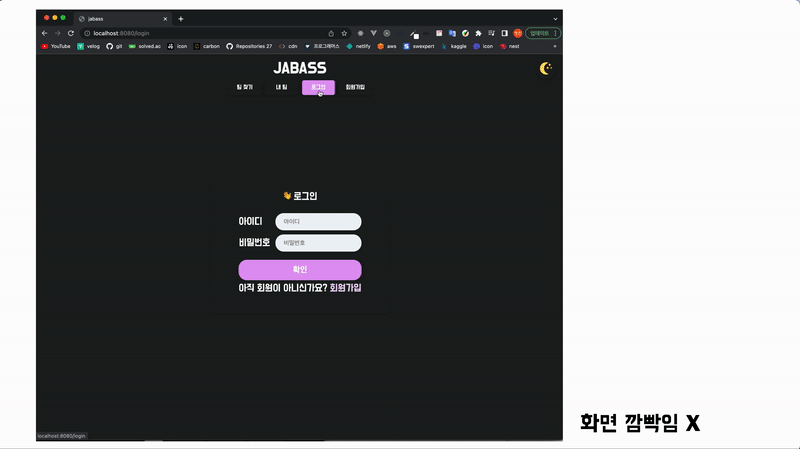
위 홈페이지는 미니 프로젝트 때 만들었던 SPA입니다. 링크를 눌러도 화면의 깜빡임 없이 바로바로 반응하는 것을 볼 수 있습니다.
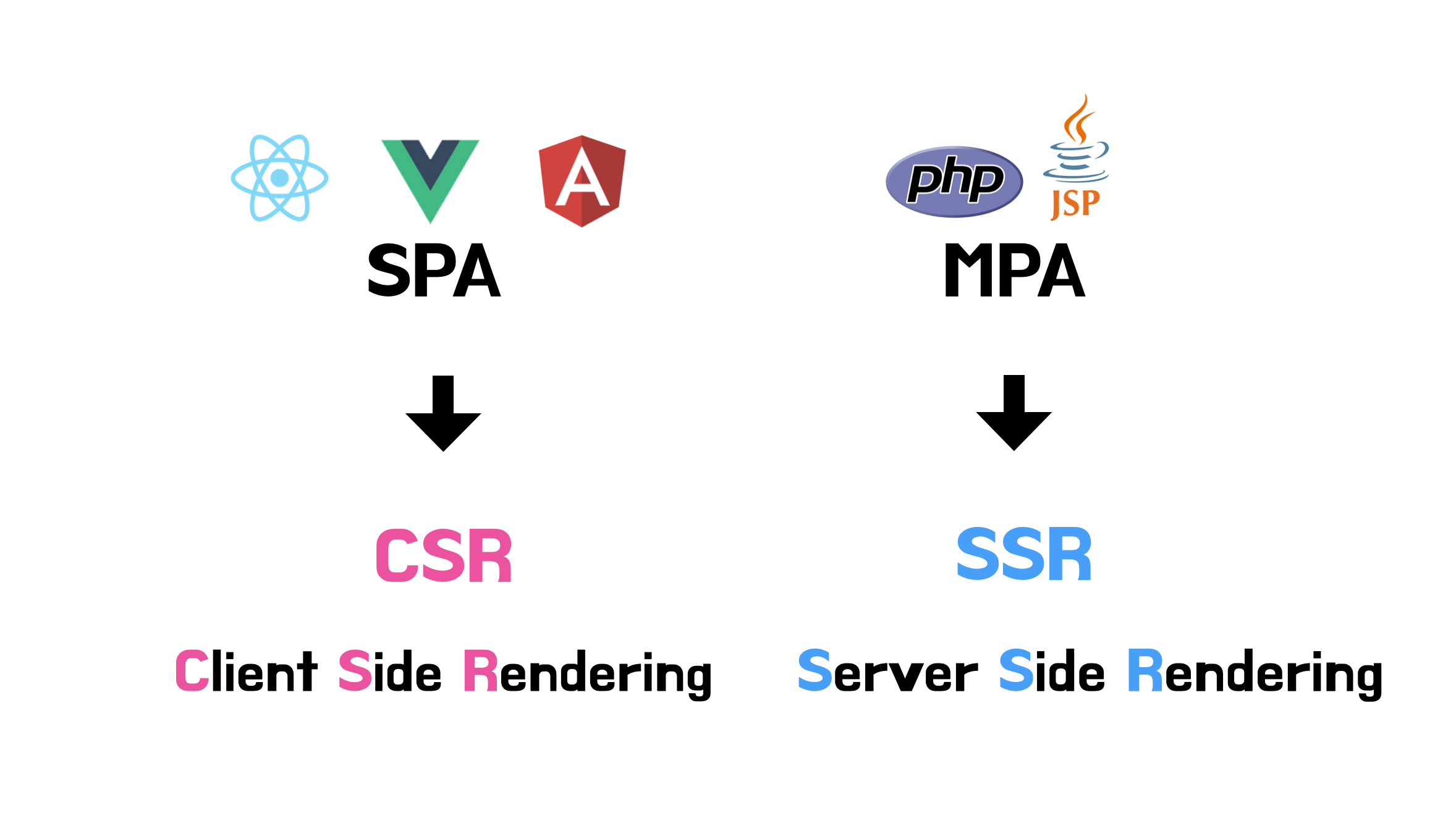
일반적으로 SPA에서는 렌더링 방식으로 CSR을 MPA에서는 렌더링 방식으로 SSR을 사용합니다. SPA는 웹 애플리케이션에 필요한 정적 리소스를 처음 한번만 다운로드하고 그 이후 새로운 페이지 요청이 있을 때만 데이터를 전달받아서 클라이언트에서 페이지를 갱신하기 때문에 자연스럽게 CSR을 사용하게 되고, MPA는 새로운 요청이 있을 때마다 서버에서 이미 렌더링된 정적 리소스를 받아오기 때문에 렌더링 방식으로 자연스럽게 SSR을 사용하게 됩니다.

CSR에 대해서 좀 더 자세히 알아보겠습니다. 유저가 웹사이트를 방문하면 서버는 빈 뼈대 HTML과 연결된 JS링크를 줍니다. 브라우저는 JS를 다운로드하고 실행합니다. 그리고 JS가 동적으로 DOM을 만들어서 브라우저에 띄워줍니다.
CSR은 JS가 동적으로 DOM을 만들기 때문에 초기 로딩 속도가 느립니다. 하지만 로딩이후에는 빠르게 동작한다는 장점이 있습니다.
유저가 컨텐츠를 보는 시간까지를 Time To View 즉, TTV 라고 하고 유저가 컨텐츠와 상호 작용을 할 수 있는 시간을 Time To Interact 즉 , TTI라고 하는데 CSR은 이 둘이 일치한다는 장점이 있습니다.

다음으로 SSR에 대해서 자세히 알아보도록 하겠습니다. 우선 웹사이트에 방문하면 서버는 렌더링 준비를 마친 HTML을 줍니다. 브라우저는 HTML을 렌더링하고, JS를 다운로드한 후 연결합니다. 이는 초기 로딩 속도가 매우 빠르다는 장점이 있습니다. 하지만 이 시점에는 사용자가 버튼을 클릭하거나 이동하려고 해도 아무 반응이 없을 수 있습니다. 인터렉션 가능한 페이지처럼 보이지만 실제로는 내용과 스타일이 입혀진 껍데기에 불과하고 JS로직이 모두 연결될 때까지 사용자의 입력에 응답할 수 없기 때문입니다. 그래서 SSR페이지는 TTV와 TTI가 다르다는 특징이 있습니다. 또한 SSR은 SEO(Search Engine Optimization), 즉 검색엔진 최적화에 유리합니다.

이제 브라우저에 대해서 이야기를 해보도록 하겠습니다. 브라우저의 주요 기능은 사용자가 요청한 자원을 서버에 요청하고 브라우저에 표시하는 것 입니다.
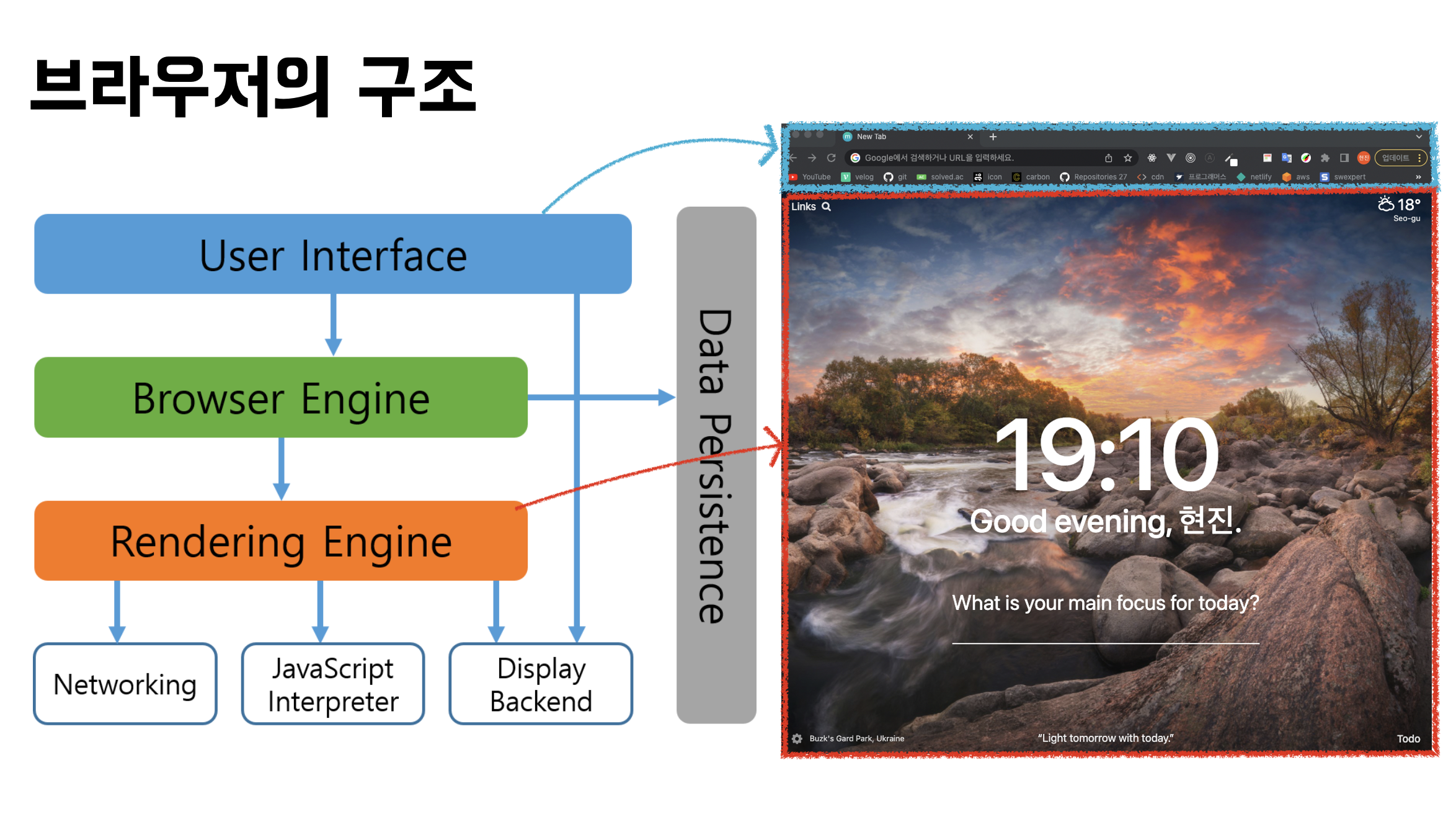
브라우저에 대해서 이해하기 위해 브라우저가 어떻게 구성되어있는가 살펴보겠습니다. 우선 유저인터페이스는 주소표시줄이나, 이전/다음버튼, 새로고침 버튼등 유저가 상호작용할 수 있는 부분들을 의미합니다.
렌더링엔진은 요청한 콘텐츠, 즉 HTML이나 CSS를 파싱하여 화면에 표시하는 역할을 하고, 브라우저 엔진은 유저인터페이스와 렌더링 엔진 사이의 동작을 제어하는 역할을 합니다. Networking은 HTTP요청과 같은 네트워크 호출에 사용되고, JavaScript Interpreter는 자바스크립트 코드를 해석하고 실행합니다. 대표적으로 크롬의 V8엔진을 예로 들 수 있습니다. Display Backend 는 기본적인 위젯을 그리는 역할을 하고, Data Persistance는 Local Storage나 쿠키등 클라이언트 사이드에서 데이터를 저장하는영역을 의미합니다.
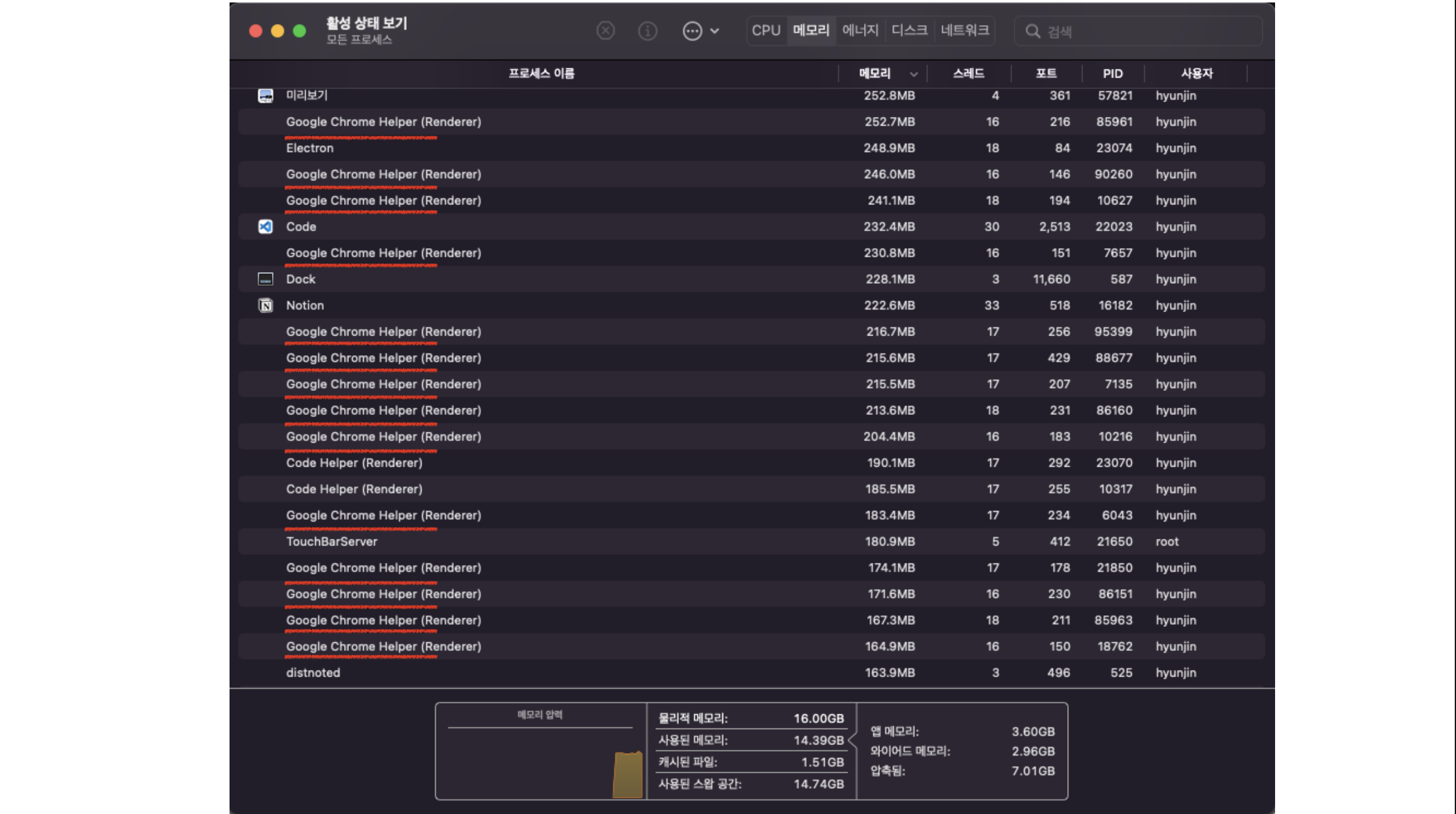
작업관리자나 활성 상태보기를 했을 때 이렇게 크롬의 프로세스가 많이 떠있는 것을 보신적이 있으신가요? 크롬창을 여러개 띄우면 왜 이렇게 많은 프로세스들이 실행되는 것인지 방금 살펴본 브라우저의 구조를 중심으로 알아보도록 하겠습니다.
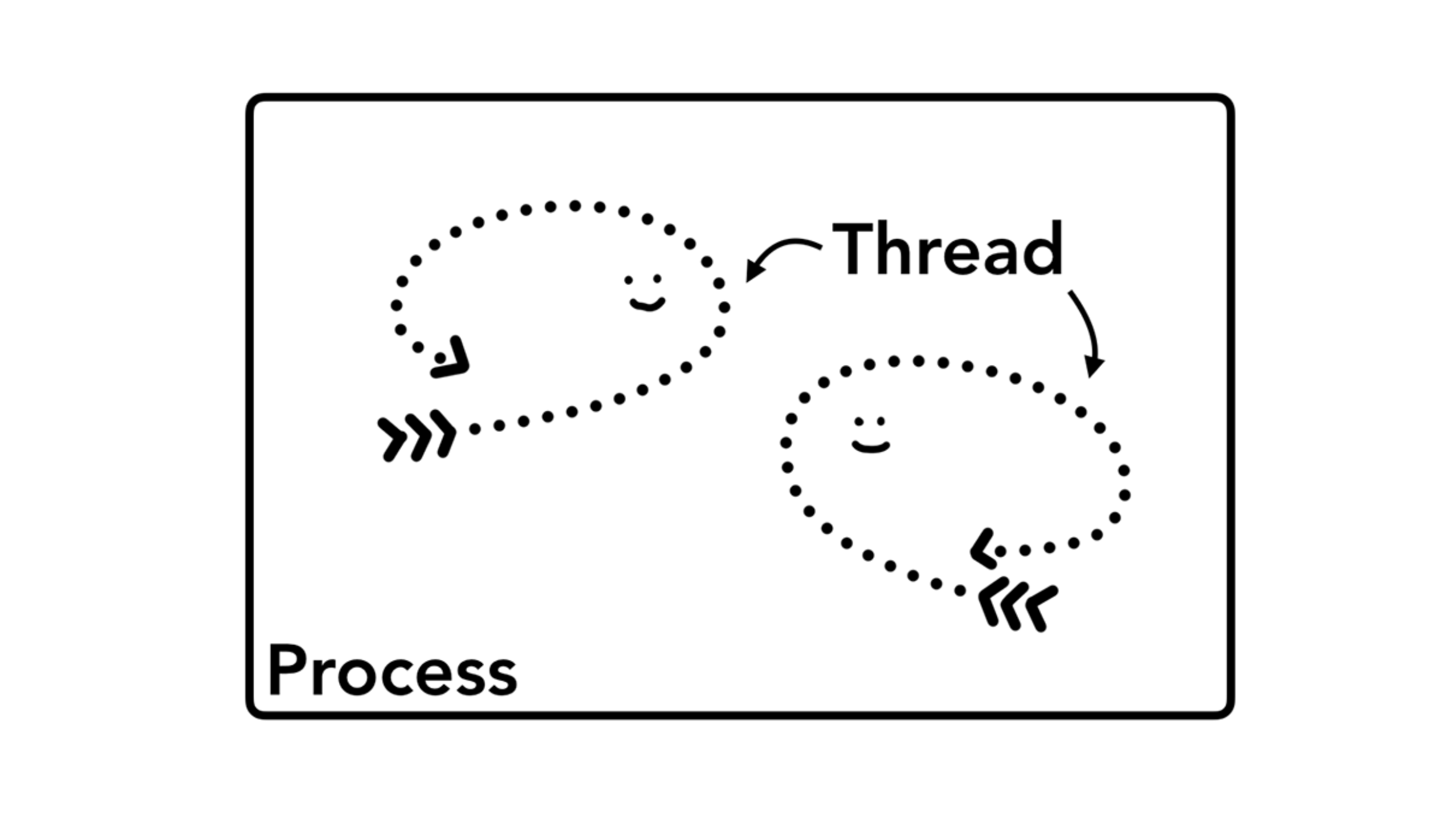
브라우저도 프로그램이기 때문에 실행시키면 프로세스가 생성됩니다. 프로세스는 컴퓨터 프로그램의 인스턴스입니다. 스레드는 프로세스 내부에 있으며 프로세스로 실행되는 프로그램의 일부를 실행합니다.
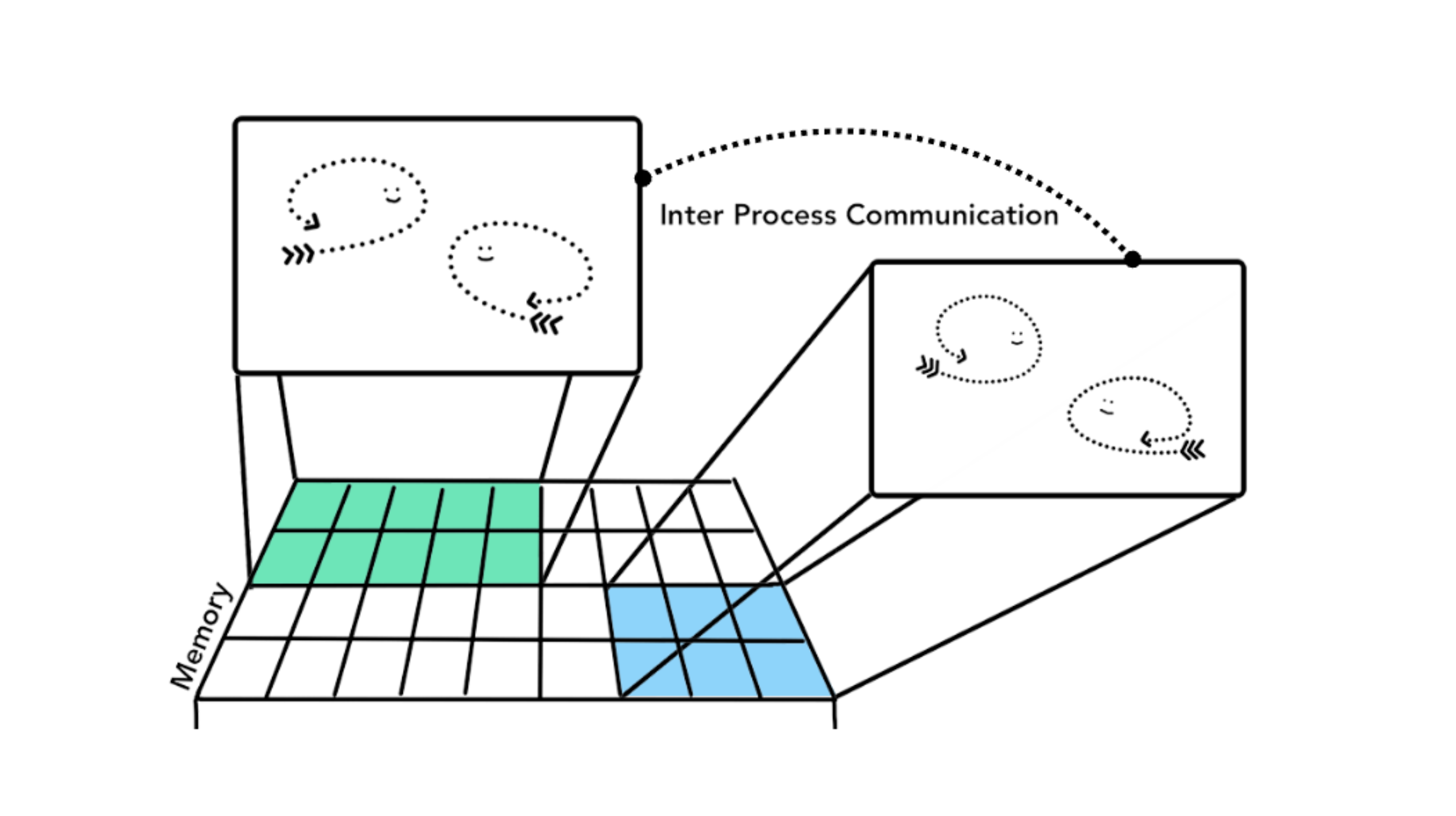
프로세스는 여러 작업을 수행하기 위해 운영체제에 다른 프로세스를 실행하라고 요청할 수 있습니다. 그러면 메모리의 다른 부분에 새 프로세스가 할당됩니다. 두 프로세스가 서로 정보를 공유해야 할 때는 IPC 즉, 프로세스 간 통신를 사용합니다. 많은 애플리케이션이 이러한 방식으로 작동하도록 설계되어 있습니다. 그래서 작업 프로세스가 응답하지 않을 때 애플리케이션의 다른 부분을 실행하는 프로세스를 중지하지 않고도 응답하지 않는 프로세스를 다시 시작할 수 있습니다.
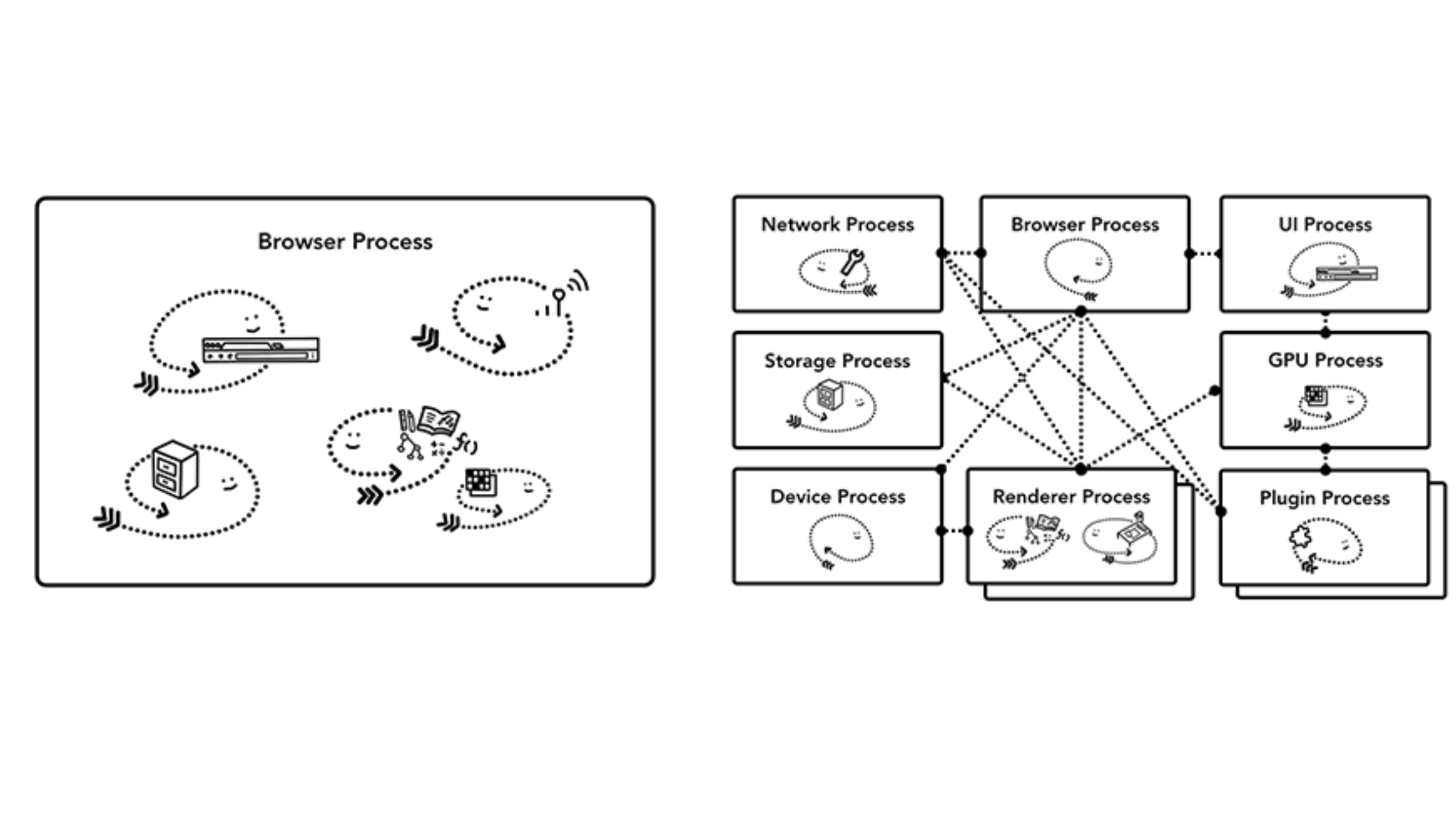
브라우저는 프로세스와 스레드를 어떻게 사용할까요?
프로세스를 한개만들고 여러개의 스레드를 사용할 수도 있고, 프로세스를 여러개 만들고 그안에 스레드를 조금만 만들어 IPC로 통신할 수도 있습니다. 왼쪽그림은 브라우저 프로세스 한개에 스레드가 여러개 있는 브라우저 구조이고, 오른쪽 그림은 프로세스 여러개를 사용하는 브라우저 구조입니다.
여기에서 주목해야 할 중요한 점은 브라우저마다 이를 다르게 구현할 수 있다는 점 입니다.
브라우저를 만드는 방법에 대한 표준은 없고, 브라우저마다 접근 방식이 완전히 다를 수 있습니다.

그렇다면 크롬은 어떨까요? 크롬은 다중 프로세스 아키텍처입니다. 탭마다 프로세스를 할당하는 방법을 process per tab이라고 하고, 사이트마다 프로세스를 할당하는 방법을 process per site 라고 하는데 크롬은 아래 링크에서 이를 설정할 수 있도록 해놨습니다.
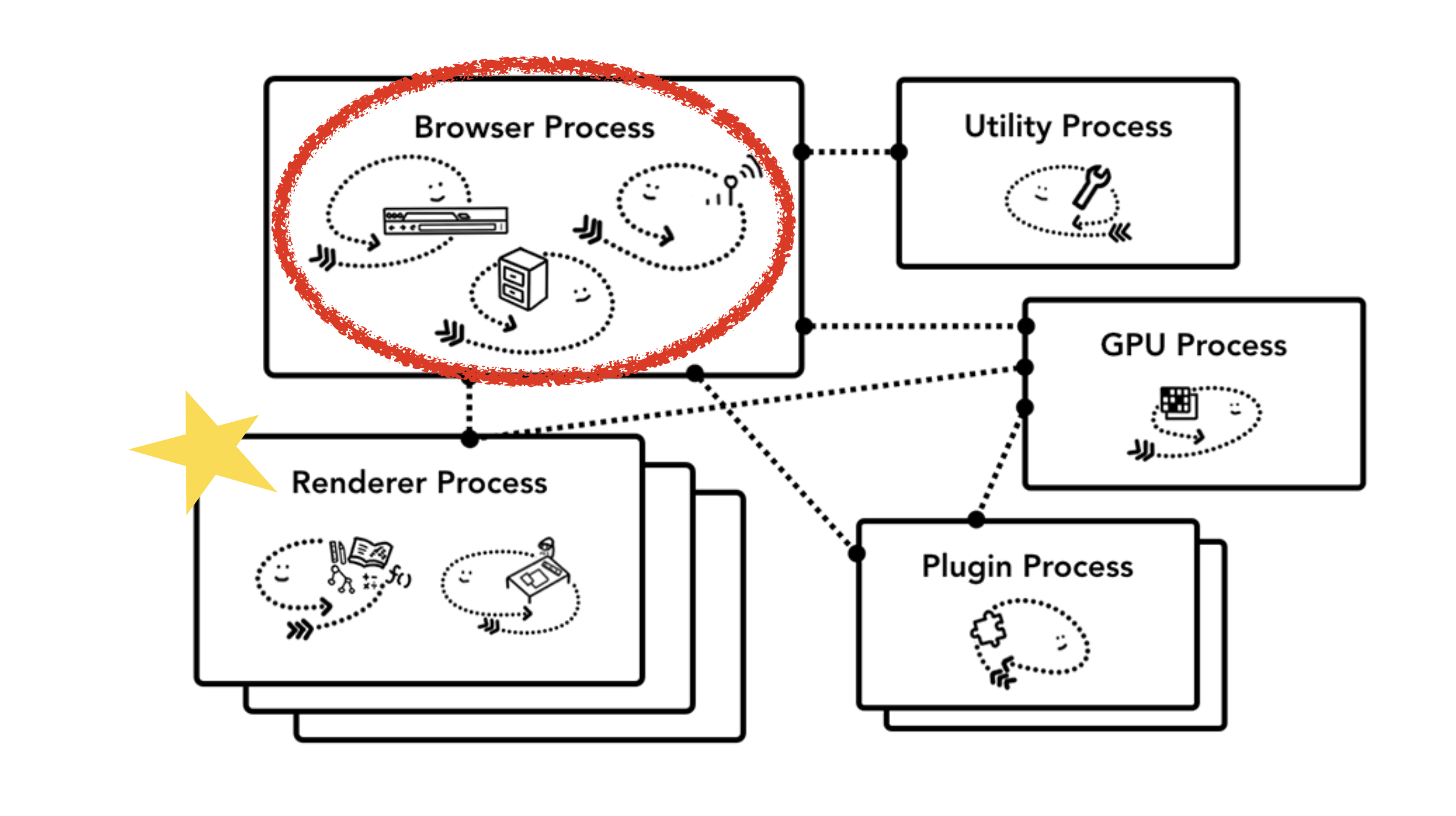
브라우저에서 제일 위에 있는 브라우저 프로세스는 어플리케이션의 각 부분을 맡고 있는 프로세스를 조정합니다. 또한 렌더러 프로세스는 여러개 만들어져서 각 탭마다 할당됩니다.
이제 브라우저의 렌더러 프로세스가 HTML, CSS, JavaScript를 화면에 어떻게 그리는가에 대해서 알아보겠습니다.
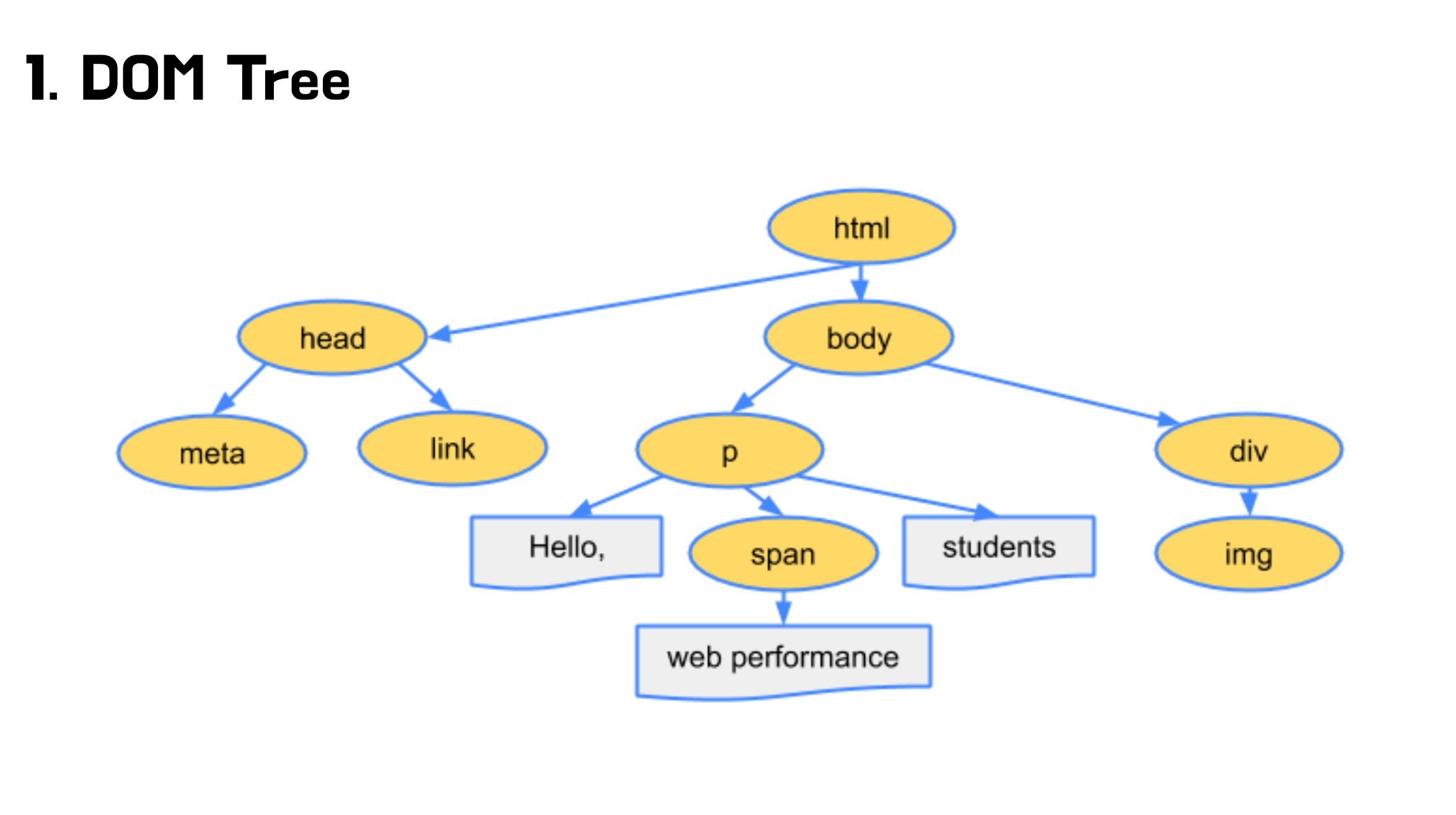
첫번째로 렌더러 프로세스는 우선 서버로 부터 전송받은 HTML을 파싱해서 DOM Tree를 구축합니다.
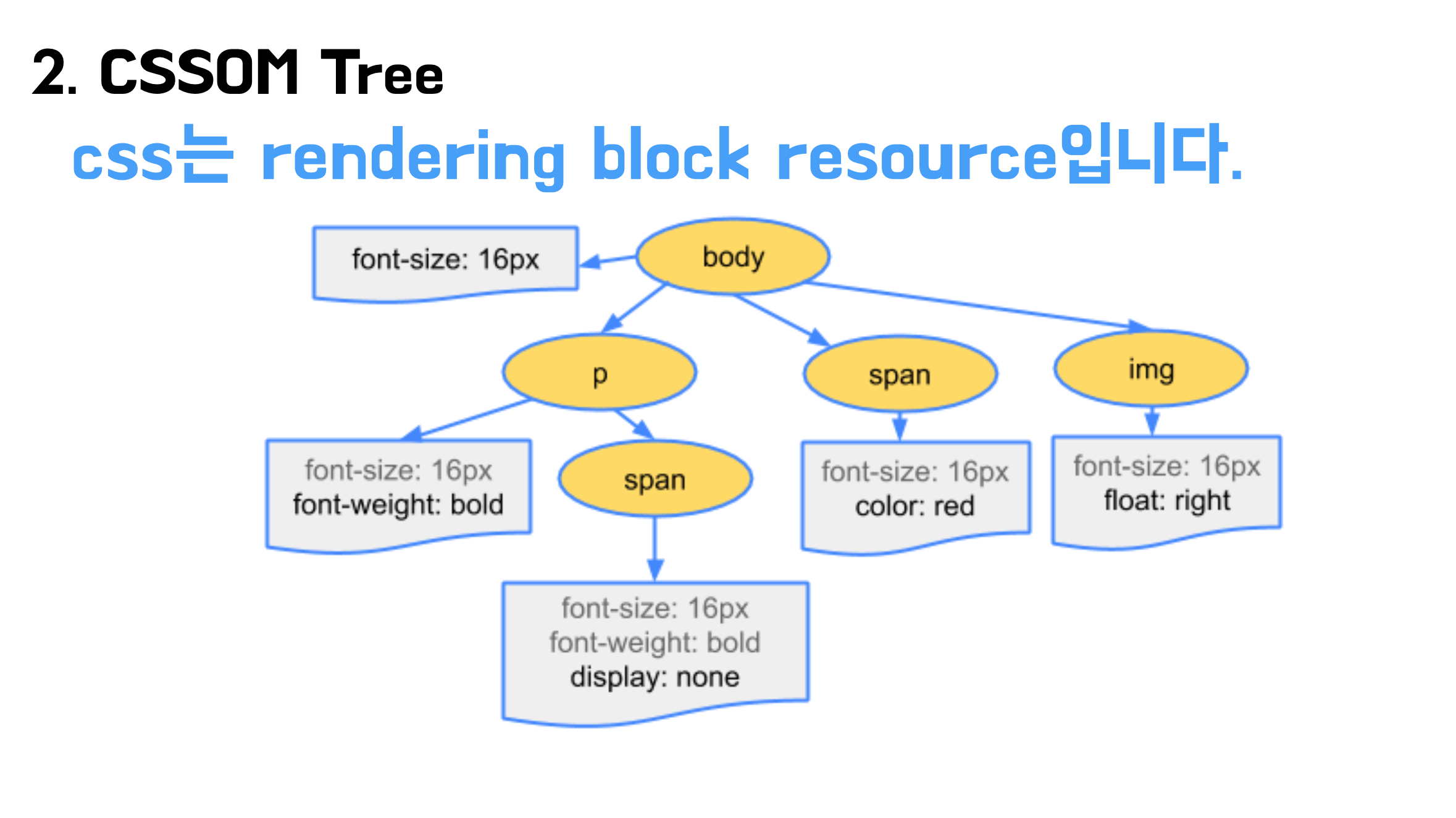
두번째로는 CSS를 파싱해서 CSS Object Model 트리를 구축합니다.
CSS는 렌더링을 할 때 반드시 필요한 리소스이기 때문에 render blocking resource 입니다. 렌더링을 막기 때문에 브라우저는 빠르게 CSS를 다운로드하는 것이 좋습니다. 따라서 HTML의 head태그 안에서 정의하여 빠르게 리소스를 받을 수 있도록 해야 합니다. (CSS는 브라우저에 캐시 처리 가능)
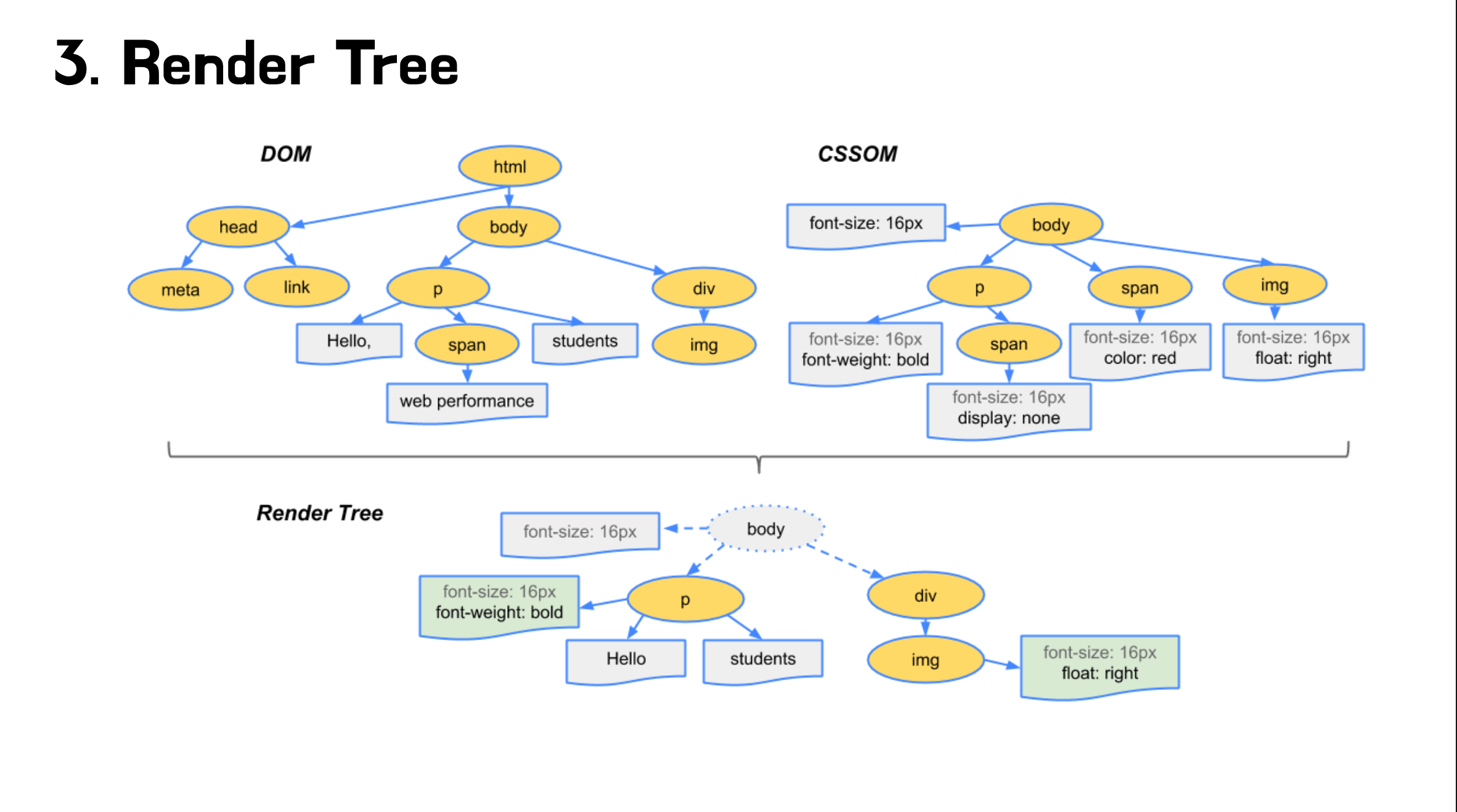
세번째로 DOM트리와 CSSOM트리를 합쳐서 Render Tree를 구성합니다.

다음으로 레이아웃입니다. 기기의 뷰포트 내에서 렌더 트리의 노드가 정확한 위치와 크기를 계산하는 과정을 말합니다. 모든 상대적인 측정값은 화면에서 절대적인 픽셀로 변환되서 각 노드들이 어디에 배치되어야 할지 계산합니다.

렌더 트리의 각 노드를 화면의 실제 픽셀로 나타내는 과정을 Painting라고 합니다. Painting 과정 후 브라우저 화면에 UI가 나타나게 됩니다.

마지막으로 정리하고 마치도록 하겠습니다.
브라우저의 Renderer 프로세스에 의해 실행되는 브라우저가 화면에 HTML, CSS, JavaScript 를 그리는 과정을 Critical Rendering Path, 즉 CRP 라고 합니다.
첫번째로 HTML을 파싱해서 Document Object Model 트리를 만들고 CSS를 파싱해서 CSS Object Model 트리를 만듭니다. 이 둘을 결합해서 렌더트리를 만들고 이 렌더 트리를 어디다 배치할지 계산하는 과정 Layout 과정을 거치고, 마지막으로 화면에 그리는 Paint과정을 거쳐서 사용자에게 화면을 보여줍니다. (Layout이 다시 진행되는 것을 Reflow, Paint가 다시 진행되는 것을 RePaint라고 합니다.)
이렇게 웹의 역사 및 브라우저, 그리고 CRP에 대해 알아봤습니다.
이 발표가 웹을 더 깊이있게 이해하는데 도움이 되었으면 좋겠습니다.
감사합니다.
